02 Feb 2019 - Dan Kristiansen
Inspireret af det stigende antal nyheds medier tilgængeligt på internettet, udgiver vi en brugervenlig applikation til at skabe et hurtigt nyhedsmæssigt overblik på tværs af nyhedsmedier.
Der findes allerede programmer, som kan oprette et enkelt resumé fra en enkelt artikel uden brugerinput. Disse kan reducere mængden af tekst, som brugeren skal læse, mens de vigtigste punkter opretholdes. Brugeren har dog stadig brug for at læse flere resume for at forstå alle aspekter af begivenheden.
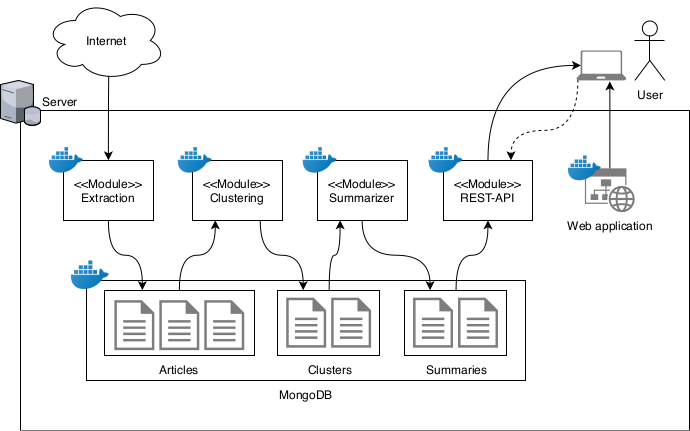
Vi anvender en ekstraktiv metode til at generere referater af et sæt nyhedsartikler. Referaterne er konstrueret gennem en række moduler. Extractor modulets opgave er kontinuerligt at samle nye artikler i en database, hvorefter artiklerne er grupperet af Clustering modulet, baseret på artiklernes indhold. Summarizer modulet laver referater af de grupperede artikler. Modulerne er udviklet til at køre i Docker containers, hvilket giver et abstraktionslag som simplificerer opsætning og vedligeholdelse af maskiner for at gøre systemet skalérbart. De enkelte moduler er ligeledes implementeret med fokus på skalérbarhed, hvor beregningstunge operationer er blevet distribueret til flere processer for at effektivisere serverens ressourcer.
Jeg brugte og implementerede et docker-bibliotek kaldet Boilerpipe, som er et værktøj til at fjerne boilerplate fra nyhedsartikler, der er downloaded fra nettet. Sådan at ekstraktoren kun vil downloade indholdet af artiklen og dermed fjerne boilerplate fra teksten. Når det tekstlige indhold er trukket ud fra websiden, gemmes det i databasen. Vi ønsker dog kun en version af hver artikel i databasen, da den ellers kan forstyrre clustering og multidokument summering. Vi implementerede en næsten duplikatdetektion, således at vi i tilfælde af mindre korrektioner ønsker at registrere, at to artikler er den samme artikel, og kun beholde den nyere version.
Clustering-tilgangen er en density-based clustering, der bruger Locality Sensitive Hashing til at kortlægge dokumentets funktionsvektorer i et lavere-dimensionelt rum, og derefter gemmer dette i præfiks træer, der giver mulighed for hurtig nearest neighbour.
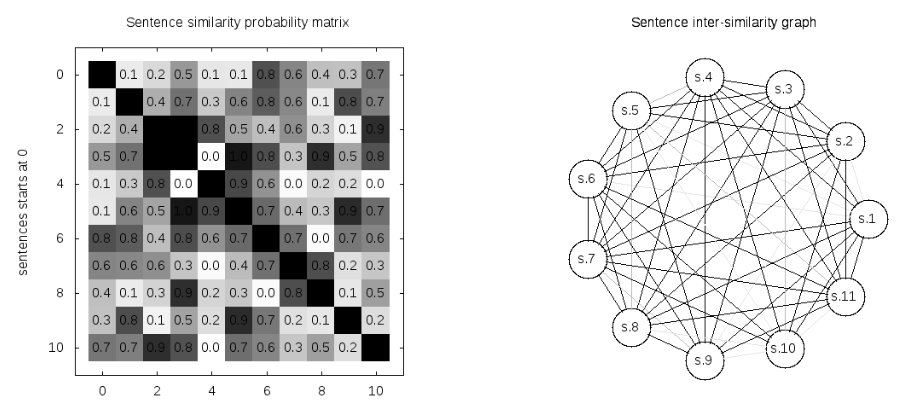 Billedet ovenfor viser ligheden mellem 10 sætninger. Til venstre er lighedssætningsmatrixen, og til højre er grafrepræsentationen af ligheden med mere de udpegede kanter, der indikerer højere lighed.
Billedet ovenfor viser ligheden mellem 10 sætninger. Til venstre er lighedssætningsmatrixen, og til højre er grafrepræsentationen af ligheden med mere de udpegede kanter, der indikerer højere lighed.
Applikationen er en fullstack-applikation implementeret med docker og Gitlab CI.