02 Feb 2019 - Dan Kristiansen
There exist summarization programs, which can create a single summary from a single article without user input. These can reduce the amount of text the user has to read while maintaining the key points. However, the user still needs to read multiple summaries, to understand all aspects of the event.
I used and implemented a docker library called Boilerpipe, which is a tool to remove Boilerplate from newsarticles extracted from the web. Such that, the extractor would only extract the content of the article, and hence, remove the boilerplate from the extracted text. When the textual content has been extracted from the webpage, it is stored in the database. However, we only want one version of each article in the database since it otherwise may bias the clustering and multi-document summarization. We implemented a Near duplicate detection, such that, in the case of minor corrections we want to detect that two articles is the same article, and only keep the newer version.
The clustering approach is a density-based clustering that uses Locality Sensitive Hashing to map the feature vectors of the documents into a lower-dimensional space, and then stores this in prefix trees, which allows for fast nearest neighbour finding.
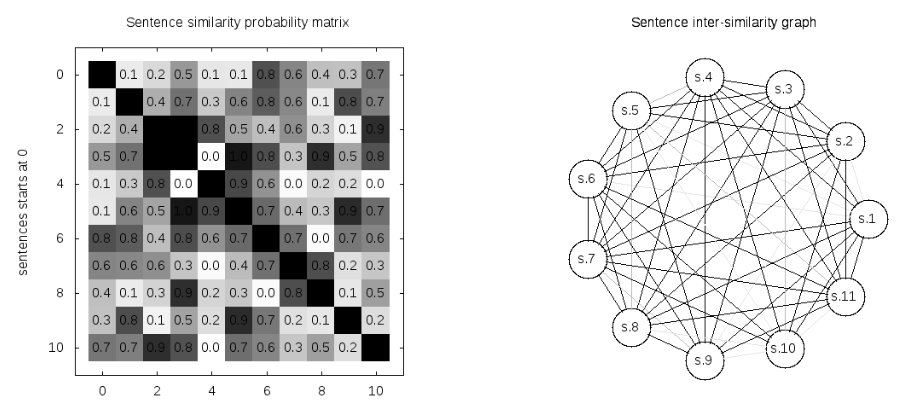 The picture above depict the similarity between 10 sentences. To the left is the similarity sentence matrix, and to the right is the graph representation of the similarity with more the pronounced edges indicating higher similarity.
The picture above depict the similarity between 10 sentences. To the left is the similarity sentence matrix, and to the right is the graph representation of the similarity with more the pronounced edges indicating higher similarity.
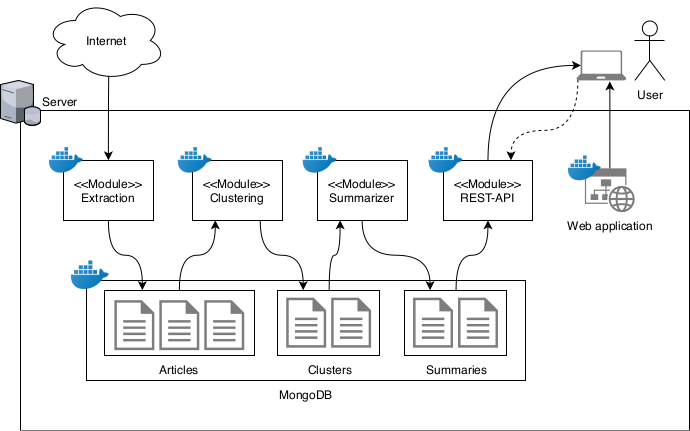
The application is a full stack application implemented with docker and Gitlab CI.